Welcome to Regular Expression
欢迎来到正则表达式。
说起正则表达式,我能想到的运用似乎有很多,比方说最简单的表单验证,以及还有一些过滤等等都需要用到正则匹配。
简单的示例:
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符(-),并设置用户名的长度,我们就可以使用以下正则表达式来设定。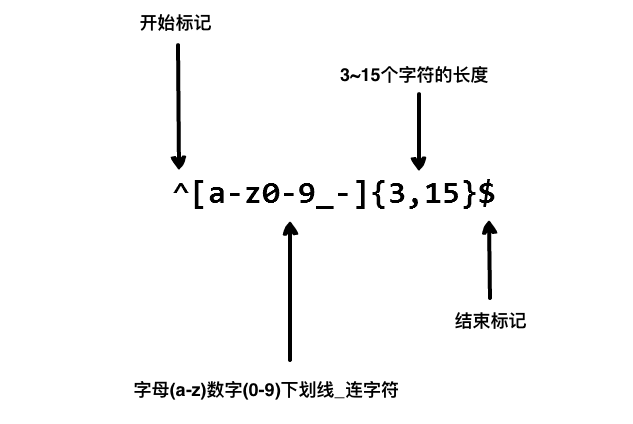
写在前面
虽然很多时候觉得在开发工程当中,只需要搬运常用的正则表达式就可以完成相关过滤,可在完成了上一天的学习之后让我觉得如果不了解正则匹配的原理,在安全的路上恐怕是行不通的,因此对正则匹配进行了相关展开。
正则基础知识
在知乎上查到很好理解的方法—先从元字符开始。
元字符是元字符是构造正则表达式的一种基本元素
元字符
| 元字符 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母、数字或下划线或汉字 |
| \s | 匹配任意空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符的开始 |
| $ | 匹配字符的结束 |
| - | 表示范围 |
| [ ] | 匹配括号中的任意一个字符 |
| *、+、? | 量词 |
知道一部分元字符,既可以根据元字符写简单的正则匹配。
匹配ab开头的字符串
1
\bab
匹配8位的QQ号码
1 | ^\d\d\d\d\d\d\d\d$ |
- 匹配手机号
1 | ^1\d\d\d\d\d\d\d\d\d\d\d$ |
- 匹配银行卡号是14~18位的数字:
1 | ^\d{14,18}$ |
- 匹配以a开头的,0个或多个b结尾的字符串
1 | ^ab*$ |
重复限定符
借用知乎大佬的一幅图,总结了比较好的限定符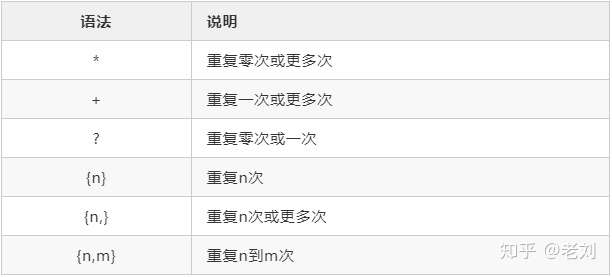
上面的4.就是eg
- 匹配银行卡号是14~18位的数字:
1 | ^\d{14,18}$ |
分组
正则表达式中用小括号()来做分组,也就是括号中的内容作为一个整体。eg:匹配ab
1 | ^(ab)* |
转义
如果想要匹配的正是括号,则需要转义
1 | ^(\(ab\))* |
断言
Assertions include boundaries, which indicate the beginnings and endings of lines and words, and other patterns indicating in some way that a match is possible (including look-ahead, look-behind, and conditional expressions).
来看MDN的一个eg
1 | const text = 'A quick fox'; |
边界类断言
| 字符 | 含义 |
|---|---|
^ |
匹配输入的开头。如果多行模式设为 true,^ 在换行符后也能立即匹配,比如 /^A/ 匹配不了 “an A” 里面的 “A”,但是可以匹配 “An A” 里面第一个 “A”。^ 出现在集合或范围开头时的含义与此不同(参见 group)。 |
$ |
匹配输入的结束。如果多行模式设为 true,^ 在换行符前也能立即匹配,比如 /t$/ 不能匹配 “eater” 中的 “t”,但是可以匹配 “eat” 中的 “t”。 |
\b |
匹配一个单词的边界,这是一个字的字符前后没有另一个字的字符位置, 例如在字母和空格之间。需要注意的是匹配的单词边界不包括在匹配中。换句话说,匹配字边界的长度为零。一些例子:/\bm/ 在 “moon” 中匹配到 “m” /oo\b/ 在 “moon” 中不会匹配到 “oo”, 因为 “oo” 后面跟着 “n” 这个单词字符./oon\b/ 在 “moon” 中匹配 “oon”, 因为 “oon” 是这个字符串的结尾, 因此后面没有单词字符/\w\b\w/ 将永远不会匹配任何东西,因为一个单词字符后面永远不会有非单词字符和单词字符。匹配退格字符 ([\b]). |
\B |
匹配非单词边界。这是上一个字符和下一个字符属于同一类型的位置:要么两者都必须是单词,要么两者都必须是非单词,例如在两个字母之间或两个空格之间。字符串的开头和结尾被视为非单词。与匹配的词边界相同,匹配的非词边界也不包含在匹配中。例如,/\Bon/ 在 “at noon” 中匹配 “on” ,/ye\B/ 在 “possibly yesterday”中匹配”ye” 。 |
其他断言
字符 |
含义 |
|---|---|
x(?=y) |
向前断言: x 被 y 跟随时匹配 x。例如,对于/Jack(?=Sprat)/,“Jack”在跟有“Sprat”的情况下才会得到匹配.`/Jack(?=Sprat |
| x(?!y) | 向前否定断言: x 没有被 y 紧随时匹配 x。例如,对于/\d+(?!\。)/,数字后没有跟随小数点的情况下才会得到匹配。对于/\d+(?!\.)/.exec(3.141),匹配‘141’而不是‘3’。 |
| (?<=y)x | 向后断言: x 跟随 y 的情况下匹配 x。例如,对于/(?<=Jack)Sprat/,“Sprat”紧随“Jack”时才会得到匹配。对于`/(?<=Jack |
| (?<!y)x | 向后否定断言: x 不跟随 y 时匹配 x。例如,对于/(?<!-)\d+/,数字不紧随-符号的情况下才会得到匹配。对于/(?<!-)\d+/.exec(3) ,“3”得到匹配。 而/(?<!-)\d+/.exec(-3)的结果无匹配,这是由于数字之前有-符号。 |
示例
使用 ^匹配输入的开头。在这个例子中,我们可以通过 /^A/ 正则表达式得到以A开头的水果。为了选择合适的水果,我们可以使用带有箭头函数的过滤方法.
1 | let fruits = ["Apple", "Watermelon", "Orange", "Avocado", "Strawberry"]; |
组和范围
| 字符集 | 含义 |
|---|---|
| `x | y` |
[xyz][a-c] |
字符集。 匹配任何一个包含的字符。您可以使用连字符来指定字符范围,但如果连字符显示为方括号中的第一个或最后一个字符,则它将被视为作为普通字符包含在字符集中的文字连字符。也可以在字符集中包含字符类。例如, [abcd] 是与[a-d].一样的,它们会 在”brisket” 中匹配 “b”,在 “chop” 中匹配 “c” .例如, [abcd-] 和[-abcd] 将会在 “brisket” 匹配 “b” , 在 “chop” 匹配 “c” , 并且匹配 “non-profit” 中的 “-“ (连字符)例如, [\w-] 是字符集 \w 和 “-”(连字符)的并集,与这种写法一样: [A-Za-z0-9_-].。他们都会 在 “brisket”中匹配 “b”, 在 “chop”中匹配 “c”, 在 “non-profit” 中匹配 “n”。 |
示例
1 | //计算元音字母数 |
写在后面
学习的大部分内容源自于MDN,同时也发现了写的很通俗易懂的文字-挂一个link
https://github.com/ziishaned/learn-regex/有一种从看文档到实际运用还有很远的感觉
附录:正则表达式中的特殊字符
摘自MDN
| 字符 | 含义 |
|---|---|
\ |
依照下列规则匹配:在非特殊字符之前的反斜杠表示下一个字符是特殊字符,不能按照字面理解。例如,前面没有 “" 的 “b” 通常匹配小写字母 “b”,即字符会被作为字面理解,无论它出现在哪里。但如果前面加了 “",它将不再匹配任何字符,而是表示一个字符边界。在特殊字符之前的反斜杠表示下一个字符不是特殊字符,应该按照字面理解。详情请参阅下文中的 “转义(Escaping)” 部分。如果你想将字符串传递给 RegExp 构造函数,不要忘记在字符串字面量中反斜杠是转义字符。所以为了在模式中添加一个反斜杠,你需要在字符串字面量中转义它。/[a-z]\s/i 和 new RegExp("[a-z]\\s", "i") 创建了相同的正则表达式:一个用于搜索后面紧跟着空白字符(\s 可看后文)并且在 a-z 范围内的任意字符的表达式。为了通过字符串字面量给 RegExp 构造函数创建包含反斜杠的表达式,你需要在字符串级别和正则表达式级别都对它进行转义。例如 /[a-z]:\\/i 和 new RegExp("[a-z]:\\\\","i") 会创建相同的表达式,即匹配类似 “C:" 字符串。 |
^ |
匹配输入的开始。如果多行标志被设置为 true,那么也匹配换行符后紧跟的位置。例如,/^A/ 并不会匹配 “an A” 中的 ‘A’,但是会匹配 “An E” 中的 ‘A’。当 ‘^‘ 作为第一个字符出现在一个字符集合模式时,它将会有不同的含义。反向字符集合 一节有详细介绍和示例。 |
$ |
匹配输入的结束。如果多行标志被设置为 true,那么也匹配换行符前的位置。例如,/t$/ 并不会匹配 “eater” 中的 ‘t’,但是会匹配 “eat” 中的 ‘t’。 |
* |
匹配前一个表达式 0 次或多次。等价于 {0,}。例如,/bo*/ 会匹配 “A ghost boooooed” 中的 ‘booooo’ 和 “A bird warbled” 中的 ‘b’,但是在 “A goat grunted” 中不会匹配任何内容。 |
+ |
匹配前面一个表达式 1 次或者多次。等价于 {1,}。例如,/a+/ 会匹配 “candy” 中的 ‘a’ 和 “caaaaaaandy” 中所有的 ‘a’,但是在 “cndy” 中不会匹配任何内容。 |
? |
匹配前面一个表达式 0 次或者 1 次。等价于 {0,1}。例如,/e?le?/ 匹配 “angel” 中的 ‘el’、”angle” 中的 ‘le’ 以及 “oslo’ 中的 ‘l’。如果紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。例如,对 “123abc” 使用 /\d+/ 将会匹配 “123”,而使用 /\d+?/ 则只会匹配到 “1”。还用于先行断言中,如本表的 x(?=y) 和 x(?!y) 条目所述。 |
. |
(小数点)默认匹配除换行符之外的任何单个字符。例如,/.n/ 将会匹配 “nay, an apple is on the tree” 中的 ‘an’ 和 ‘on’,但是不会匹配 ‘nay’。如果 s (“dotAll”) 标志位被设为 true,它也会匹配换行符。 |
(x) |
像下面的例子展示的那样,它会匹配 ‘x’ 并且记住匹配项。其中括号被称为捕获括号。模式 /(foo) (bar) \1 \2/ 中的 ‘(foo)‘ 和 ‘(bar)‘ 匹配并记住字符串 “foo bar foo bar” 中前两个单词。模式中的 \1 和 \2 表示第一个和第二个被捕获括号匹配的子字符串,即 foo 和 bar,匹配了原字符串中的后两个单词。注意 \1、\2、…、\n 是用在正则表达式的匹配环节,详情可以参阅后文的 \n 条目。而在正则表达式的替换环节,则要使用像 $1、$2、…、$n 这样的语法,例如,'bar foo'.replace(/(...) (...)/, '$2 $1')。$& 表示整个用于匹配的原字符串。 |
(?:x) |
匹配 ‘x’ 但是不记住匹配项。这种括号叫作非捕获括号,使得你能够定义与正则表达式运算符一起使用的子表达式。看看这个例子 /(?:foo){1,2}/。如果表达式是 /foo{1,2}/,{1,2} 将只应用于 ‘foo’ 的最后一个字符 ‘o’。如果使用非捕获括号,则 {1,2} 会应用于整个 ‘foo’ 单词。更多信息,可以参阅下文的 Using parentheses 条目. |
x(?=y) |
匹配’x’仅仅当’x’后面跟着’y’.这种叫做先行断言。例如,/Jack(?=Sprat)/会匹配到’Jack’仅当它后面跟着’Sprat’。/Jack(?=Sprat|Frost)/匹配‘Jack’仅当它后面跟着’Sprat’或者是‘Frost’。但是‘Sprat’和‘Frost’都不是匹配结果的一部分。 |
(?<=y)x |
匹配’x’仅当’x’前面是’y’.这种叫做后行断言。例如,/(?<=Jack)Sprat/会匹配到’ Sprat ‘仅仅当它前面是’ Jack ‘。/(?<=Jack|Tom)Sprat/匹配‘ Sprat ’仅仅当它前面是’Jack’或者是‘Tom’。但是‘Jack’和‘Tom’都不是匹配结果的一部分。 |
x(?!y) |
仅仅当’x’后面不跟着’y’时匹配’x’,这被称为正向否定查找。例如,仅仅当这个数字后面没有跟小数点的时候,/\d+(?!.)/ 匹配一个数字。正则表达式/\d+(?!.)/.exec(“3.141”)匹配‘141’而不是‘3.141’ |
(?<!*y*)*x* |
仅仅当’x’前面不是’y’时匹配’x’,这被称为反向否定查找。例如, 仅仅当这个数字前面没有负号的时候,/(?<!-)\d+/ 匹配一个数字。 /(?<!-)\d+/.exec('3') 匹配到 “3”. /(?<!-)\d+/.exec('-3') 因为这个数字前有负号,所以没有匹配到。 |
| [`x | y`](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions#special-or) |
{n} |
n 是一个正整数,匹配了前面一个字符刚好出现了 n 次。 比如, /a{2}/ 不会匹配“candy”中的’a’,但是会匹配“caandy”中所有的 a,以及“caaandy”中的前两个’a’。 |
{n,} |
n是一个正整数,匹配前一个字符至少出现了n次。例如, /a{2,}/ 匹配 “aa”, “aaaa” 和 “aaaaa” 但是不匹配 “a”。 |
{n,m} |
n 和 m 都是整数。匹配前面的字符至少n次,最多m次。如果 n 或者 m 的值是0, 这个值被忽略。例如,/a{1, 3}/ 并不匹配“cndy”中的任意字符,匹配“candy”中的a,匹配“caandy”中的前两个a,也匹配“caaaaaaandy”中的前三个a。注意,当匹配”caaaaaaandy“时,匹配的值是“aaa”,即使原始的字符串中有更多的a。 |
[xyz] |
一个字符集合。匹配方括号中的任意字符,包括转义序列。你可以使用破折号(-)来指定一个字符范围。对于点(.)和星号(*)这样的特殊符号在一个字符集中没有特殊的意义。他们不必进行转义,不过转义也是起作用的。 例如,[abcd] 和[a-d]是一样的。他们都匹配”brisket”中的‘b’,也都匹配“city”中的‘c’。/[a-z.]+/ 和/[\w.]+/与字符串“test.i.ng”匹配。 |
[^xyz] |
一个反向字符集。也就是说, 它匹配任何没有包含在方括号中的字符。你可以使用破折号(-)来指定一个字符范围。任何普通字符在这里都是起作用的。例如,[^abc] 和 [^a-c] 是一样的。他们匹配”brisket”中的‘r’,也匹配“chop”中的‘h’。 |
[\b] |
匹配一个退格(U+0008)。(不要和\b混淆了。) |
\b |
匹配一个词的边界。一个词的边界就是一个词不被另外一个“字”字符跟随的位置或者前面跟其他“字”字符的位置,例如在字母和空格之间。注意,匹配中不包括匹配的字边界。换句话说,一个匹配的词的边界的内容的长度是0。(不要和[\b]混淆了)使用”moon”举例: /\bm/匹配“moon”中的‘m’; /oo\b/并不匹配”moon”中的’oo’,因为’oo’被一个“字”字符’n’紧跟着。 /oon\b/匹配”moon”中的’oon’,因为’oon’是这个字符串的结束部分。这样他没有被一个“字”字符紧跟着。 /\w\b\w/将不能匹配任何字符串,因为在一个单词中间的字符永远也不可能同时满足没有“字”字符跟随和有“字”字符跟随两种情况。注意: JavaScript的正则表达式引擎将特定的字符集定义为“字”字符。不在该集合中的任何字符都被认为是一个断词。这组字符相当有限:它只包括大写和小写的罗马字母,十进制数字和下划线字符。不幸的是,重要的字符,例如“é”或“ü”,被视为断词。 |
\B |
匹配一个非单词边界。匹配如下几种情况:字符串第一个字符为非“字”字符字符串最后一个字符为非“字”字符两个单词字符之间两个非单词字符之间空字符串例如,/\B../匹配”noonday”中的’oo’, 而/y\B../匹配”possibly yesterday”中的’yes‘ |
\c*X* |
当X是处于A到Z之间的字符的时候,匹配字符串中的一个控制符。例如,/\cM/ 匹配字符串中的 control-M (U+000D)。 |
\d |
匹配一个数字。``等价于[0-9]。例如, /\d/ 或者 /[0-9]/ 匹配”B2 is the suite number.”中的’2’。 |
\D |
匹配一个非数字字符。``等价于[^0-9]。例如, /\D/ 或者 /[^0-9]/ 匹配”B2 is the suite number.”中的’B’ 。 |
\f |
匹配一个换页符 (U+000C)。 |
\n |
匹配一个换行符 (U+000A)。 |
\r |
匹配一个回车符 (U+000D)。 |
\s |
匹配一个空白字符,包括空格、制表符、换页符和换行符。等价于[ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。例如, /\s\w*/ 匹配”foo bar.”中的’ bar’。经测试,\s不匹配”\u180e“,在当前版本Chrome(v80.0.3987.122)和Firefox(76.0.1)控制台输入/\s/.test(“\u180e”)均返回false。 |
\S |
匹配一个非空白字符。等价于 [^ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。例如,/\S\w*/ 匹配”foo bar.”中的’foo’。 |
\t |
匹配一个水平制表符 (U+0009)。 |
\v |
匹配一个垂直制表符 (U+000B)。 |
\w |
匹配一个单字字符(字母、数字或者下划线)。等价于 [A-Za-z0-9_]。例如, /\w/ 匹配 “apple,” 中的 ‘a’,”$5.28,”中的 ‘5’ 和 “3D.” 中的 ‘3’。 |
\W |
匹配一个非单字字符。等价于 [^A-Za-z0-9_]。例如, /\W/ 或者 /[^A-Za-z0-9_]/ 匹配 “50%.” 中的 ‘%’。 |
\*n* |
在正则表达式中,它返回最后的第n个子捕获匹配的子字符串(捕获的数目以左括号计数)。比如 /apple(,)\sorange\1/ 匹配”apple, orange, cherry, peach.”中的’apple, orange,’ 。 |
\0 |
匹配 NULL(U+0000)字符, 不要在这后面跟其它小数,因为 \0<digits> 是一个八进制转义序列。 |
\xhh |
匹配一个两位十六进制数(\x00-\xFF)表示的字符。 |
\uhhhh |
匹配一个四位十六进制数表示的 UTF-16 代码单元。 |
\u{hhhh}或\u{hhhhh} |
(仅当设置了u标志时)匹配一个十六进制数表示的 Unicode 字符。 |